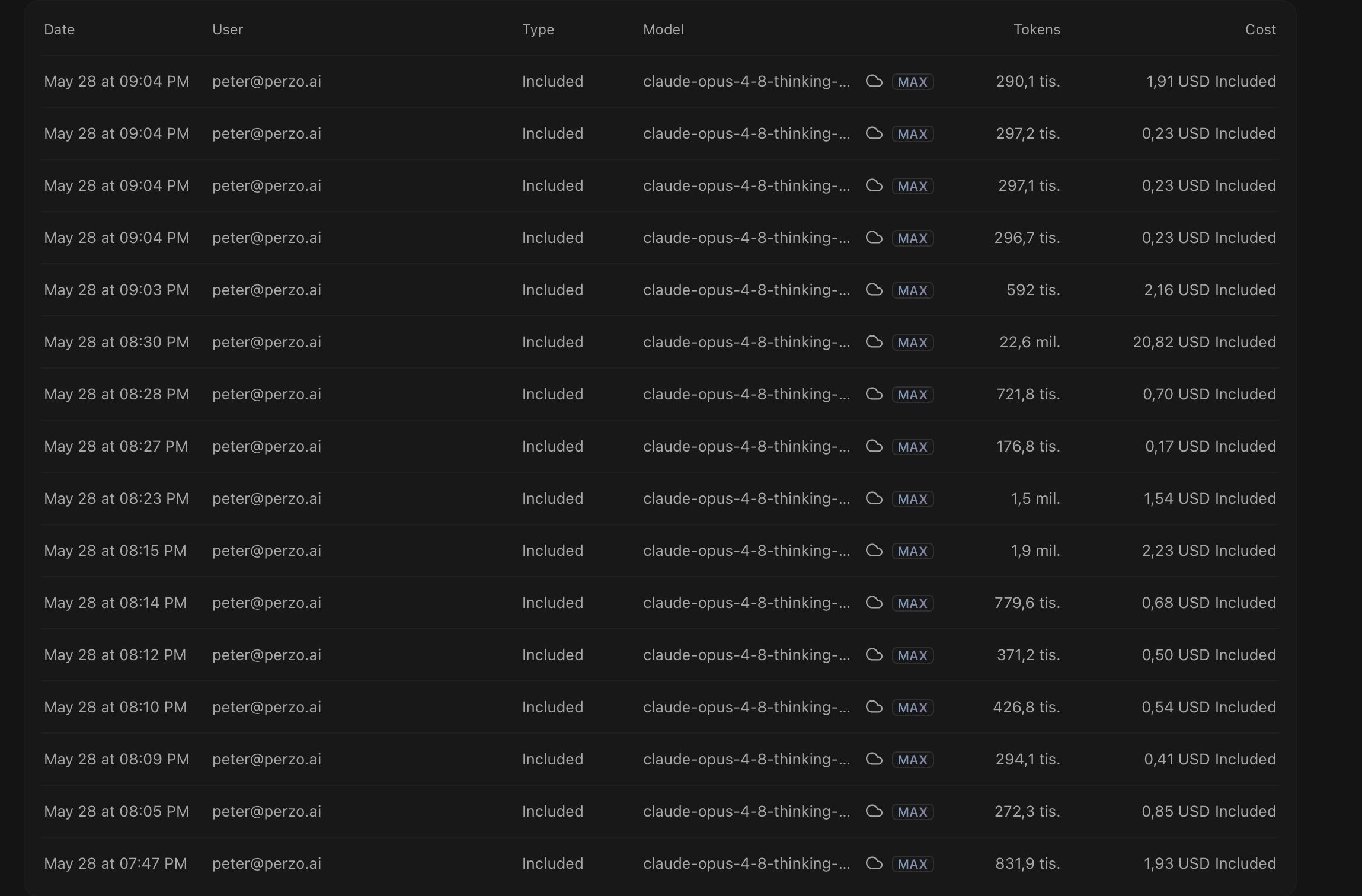
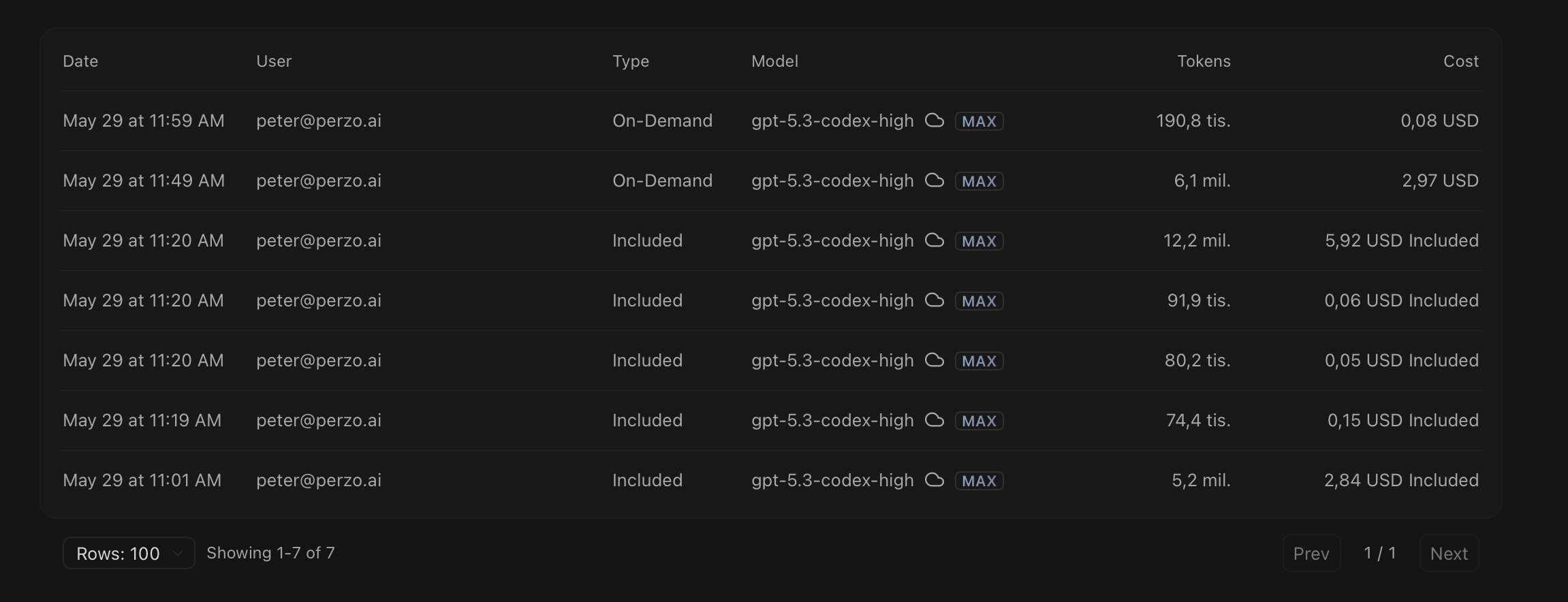
Same task. Same prompts. Two Cursor cloud agents.
Opus 4.8: ~75 min, 31.7M tokens, ~$35, 2,479 lines of core TypeScript
GPT-5.3-Codex: ~60 min, 23.9M tokens, ~$12, 1,785 lines of core TypeScript
For the data nerds: most of those tokens are cache reads — the agent re-reading its own context as it works, not fresh writing. The bill is still real.
Yes, I know — different models, different classes, one task. This isn’t a benchmark. But I run the same kind of work every day, so I wanted to see what it actually costs me in practice.
Opus spent 45 minutes “planning” before it wrote a single line, then built the bigger version. Codex just started building and shipped the same feature with 39% less code.
So what did the extra $23 buy me? Right now, nothing I can point to. More planning, more tokens, more code to maintain — but none of it adds up unless it ends up as better code. Otherwise it’s just a pricier route to the same place.
Is anyone actually getting 3x the value out of Opus, or are we just paying for the reputation?